Most people who follow my work know I run my business with an AI-first approach.
In practice, that doesn't mean "AI does everything." It means I delegate to AI every task I'm confident it can do under my oversight, and I keep a human hand on the work that carries real consequences. Right now that delegation covers a big chunk of my top-of-funnel: lead generation and initial outreach. I run a stack of tools that finds relevant prospects, researches them, and drafts a first message in my voice.
And honestly? It works. I'm getting tailored, relevant leads. The outreach lands. I'm in real conversations with real clients that I would not have had the time to start manually.
But this isn't a victory lap for automation. It's about the day the automation made me look like I didn't know my own product, and what I learned about the difference between an agent that helps your reputation and one that quietly burns it.

The incident
Last week, one of my outreach agents reached out to a promising lead. While introducing my background, it described one of my products, ClinicSynch, like this:
"...a multi-tenant platform for US clinics."
Read it quickly and it sounds fine. Professional, even. But there's a landmine in it.
"Multi-tenant" is true. ClinicSynch is genuinely a multi-tenant platform.
"US" is completely, plainly wrong.
ClinicSynch is built specifically for small-to-medium clinics operating in Pakistan. It solves problems that are unique to that ecosystem: the way appointments, payments, record-keeping, and patient communication actually work there. The Pakistani focus isn't a footnote. It's stated in the hero section on the homepage, the first thing anyone sees.
So why did the agent say "US"?
Because almost all of my past client work has been for US companies. That context was floating around in the model's view of "who Junaid is." The country of ClinicSynch was never explicitly stated in the knowledge base the agent draws from, and, importantly, the knowledge base never called it a US product either. There was simply a gap. And the model did what models do with gaps: it filled it with the most statistically plausible guess given everything else it "knew" about me.
One word. But that word silently rewrote every assumption about the product. Medical practice in the US and in Pakistan operate in completely different worlds: different regulations, different payer models, different workflows, different buyer. Saying "US" didn't just add a detail. It described a different product, for a different market, solving different problems.
The part that actually hurt
Here's what separates a typo from a trust event.
The lead was sharp. They did exactly what a good prospect does: they clicked through and looked at the site. And the site told a different story than my message did. The homepage clearly presents a product built for the Pakistani healthcare ecosystem. My outreach said "US clinics."
That mismatch did something specific and damaging. The conversation stopped being about the value I could create for their business and became about why my message said something that wasn't true. I went from "interesting person worth a reply" to "person whose claims I now need to fact-check."
Trust was gone before a relationship was ever built.
In my case, the blast radius was small: a contract worth a couple thousand dollars and a slightly awkward recovery email. Annoying, survivable, a good story.
But run that same failure mode through a different business and the numbers change fast. Imagine an agent inventing a compliance claim, a pricing term, a delivery date, a clinical capability, or a security certification, sent to the wrong client at the wrong moment. The same one-word confidence that cost me a small contract could cost another company a deal, a reputation, or a lawsuit.
That's the real lesson. The failure wasn't rare or exotic. It was mundane. And mundane failures, deployed at scale across every message your agents send, are exactly the ones worth engineering against.
Why this happens: the anatomy of a confident hallucination
It helps to be precise about what actually went wrong, because "the AI hallucinated" is too vague to fix.
Large language models don't retrieve facts the way a database does. They generate the most likely continuation of text given everything in their context. When the information they need is present and unambiguous, that continuation is usually correct. When there's a gap, the model doesn't stop and flag the gap. It produces a fluent, confident answer anyway, by leaning on whatever surrounding signal seems related.

My failure had four ingredients, and you'll recognize them in almost every agent mishap:
- A gap in the source of truth. ClinicSynch's country wasn't explicitly encoded where the agent looks.
- A strong nearby prior. "Most of Junaid's work is for US clients" was the dominant signal in context.
- No abstention. Nothing in the system let the agent say "I'm not sure which market this product serves, so I'll leave it out." It is rewarded for sounding complete, not for being cautious.
- No verification before send. The claim went straight to a human prospect with no check against the actual website or product record.
Notice that only the first ingredient is about "bad data." The other three are about system design. That's the good news: you can't make a model omniscient, but you absolutely can build a system that refuses to state things it can't support. That system is what we call guardrails.
So what are guardrails, really?
"Guardrails" gets thrown around as a buzzword, so let me be concrete. A guardrail is any mechanism that constrains what your AI can do, say, or assume, so that a failure of the model becomes a non-event instead of an incident.
Guardrails are not one thing. They're a stack of independent checks, each catching a different class of failure. Think of it like defense in depth: no single layer is perfect, but a determined error has to get past all of them to reach your customer.
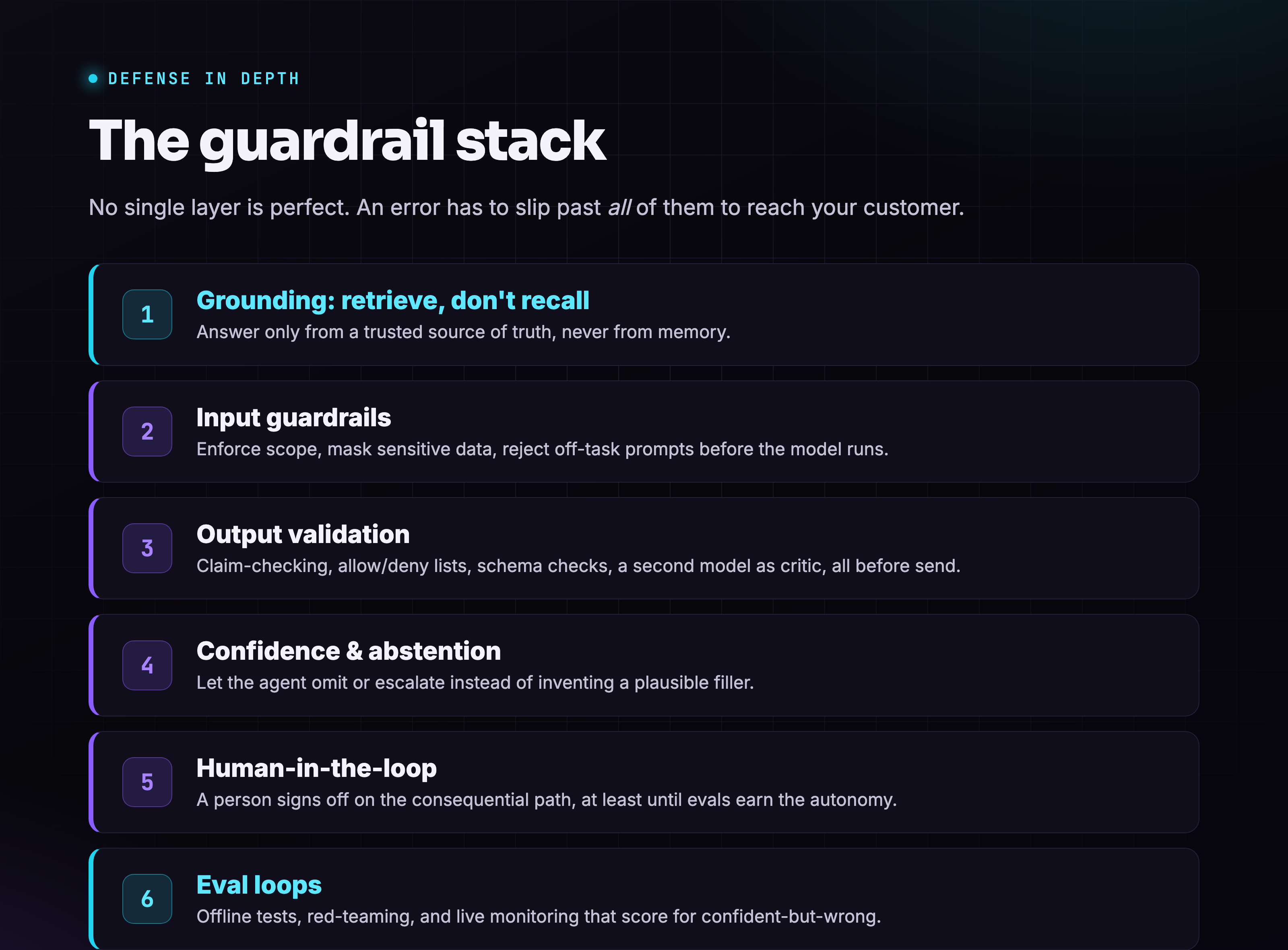
Here are the layers that matter, roughly in the order a request flows through them.
1. Grounding: retrieve, don't recall
The single highest-leverage guardrail. Instead of letting the model answer about my products from memory, force it to pull from a trusted source of truth (a product database, the live website, a vetted fact sheet) and answer only from what it retrieved. If ClinicSynch's record had said market: Pakistan and the agent were instructed to describe products strictly from that record, the "US" claim could never have formed. Grounding turns "what does the model believe?" into "what does the record say?"
2. Input guardrails: control what goes in
Before the model even runs, validate and shape the request: enforce scope ("only discuss products in the approved catalog"), strip or mask sensitive data, reject prompts that try to push the agent off-task. A lot of bad outputs are really bad inputs that were never caught.
3. Output validation: check what comes out
After the model generates but before anything is sent, run the draft through checks:
- Claim verification: does every factual statement appear in the grounded source? Flag or strip any that don't.
- Allow/deny lists: never let certain words or claims through (e.g., the word "US" attached to a Pakistan-only product, unverified certifications, specific pricing).
- Schema/format checks: the output must match an expected structure.
- A second model as a critic: a separate "judge" pass asks "is anything here unsupported by the source?" before release.
4. Confidence and abstention: let it say "I don't know"
Most hallucinations happen because the system gives the model no acceptable way to be uncertain. Build one. Let the agent omit a detail it can't ground, or escalate to a human, rather than inventing a plausible filler. An agent that leaves out the market is strictly better than one that guesses the wrong market.
5. Human-in-the-loop: a person on the consequential path
Not every action needs a human, but outbound messages that represent you to a stranger probably do, at least until your evals prove the lower layers are trustworthy. The art is choosing where the checkpoint sits: review every first-touch message, or only the ones the system flags as low-confidence or high-stakes. Human-in-the-loop isn't the absence of automation; it's automation that knows when to ask.
6. Eval loops: measure failure on purpose, continuously
Everything above is a hypothesis until you test it. An eval loop is a standing test suite for your agent's behavior:
- Offline evals: a fixed set of tricky cases (including "describe ClinicSynch") that you re-run on every change, scoring for confident-but-wrong answers specifically.
- Red-teaming: deliberately probing for the gaps where the model is tempted to guess.
- Online monitoring: logging real outputs, sampling them for accuracy, and feeding failures back into the offline set.
Evals are what turn a one-time fix into a system that stays fixed as your products, prompts, and models change underneath you.
A practical starting point
You don't need all six layers on day one. If you're deploying customer-facing agents and want the highest return for the least effort, do these three first:
- Ground every factual claim in a source of truth, and instruct the agent to describe things only from that source.
- Add an output check that refuses to send any claim it can't trace back to the source, plus an allow/deny list for the handful of things you absolutely can't get wrong.
- Keep a human on first-touch outreach until your evals show the agent earns the autonomy.
Then build the eval loop so the system gets more trustworthy over time, not less.
I'm not quitting agents. I'm caging the guesswork.
I want to be clear, because this could read as an anti-AI cautionary tale and it absolutely is not. Agents still generate a steady stream of opportunities I could never create by hand. The leverage is real. I'm not giving that up.
What I'm giving up is the assumption that fluent means correct. An agent that writes a confident, well-structured sentence has told you nothing about whether that sentence is true. The entire job of guardrails is to close the gap between "sounds right" and "is right" before that gap reaches a customer.
So my next build isn't a fancier agent. It's tighter controls and stronger eval loops around every agent that speaks on my behalf.
The one question worth answering
If you're deploying AI in any customer-facing workflow: what, specifically, stops your agent from confidently stating something that isn't true? If you can't answer that in one sentence, that's your next project.
Building or deploying agents and want them to be reliable, not just impressive? Grounding, guardrails, and eval loops are exactly the kind of work I do. Let's talk.